
NODES POWERING OFF AT RANDOM
Pages: 1 2

neiltorda
99 Posts
July 10, 2022, 3:20 amQuote from neiltorda on July 10, 2022, 3:20 amWe had a major network outage at our site today, where half of our network went offline. 3 of our 6 nodes went offline so we shut everything down until the network could be restored.
I have been trying to get the petasan system back online, but as some nodes come up, others go offline.
The most I have been able to get online at any one time is 5. As soon as the sixth one comes online, various others (sometimes 1, sometimes 2 and at other times 3) nodes will just power off.
The Node list will at times show all 6 nodes being online, when i know for a fact some of the nodes are physically powered down.
The pools will not all come back online and no data can be served.
Any idea what steps should be taken to get the system stable and back up?
Thanks
Neil
We had a major network outage at our site today, where half of our network went offline. 3 of our 6 nodes went offline so we shut everything down until the network could be restored.
I have been trying to get the petasan system back online, but as some nodes come up, others go offline.
The most I have been able to get online at any one time is 5. As soon as the sixth one comes online, various others (sometimes 1, sometimes 2 and at other times 3) nodes will just power off.
The Node list will at times show all 6 nodes being online, when i know for a fact some of the nodes are physically powered down.
The pools will not all come back online and no data can be served.
Any idea what steps should be taken to get the system stable and back up?
Thanks
Neil
neiltorda
99 Posts
July 10, 2022, 3:34 amQuote from neiltorda on July 10, 2022, 3:34 amThis is some of the items that are showing up in the console of nodes.
This is from a node that is starting up:
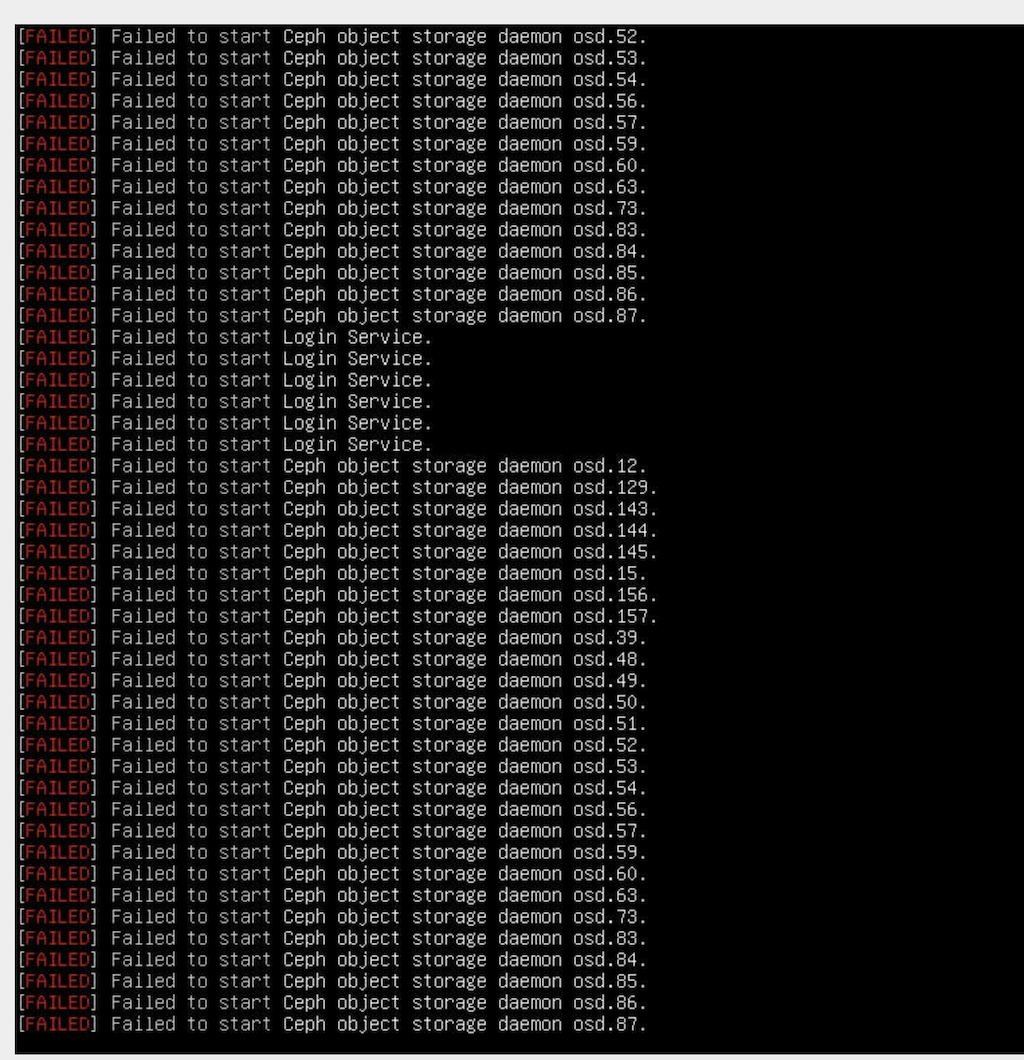
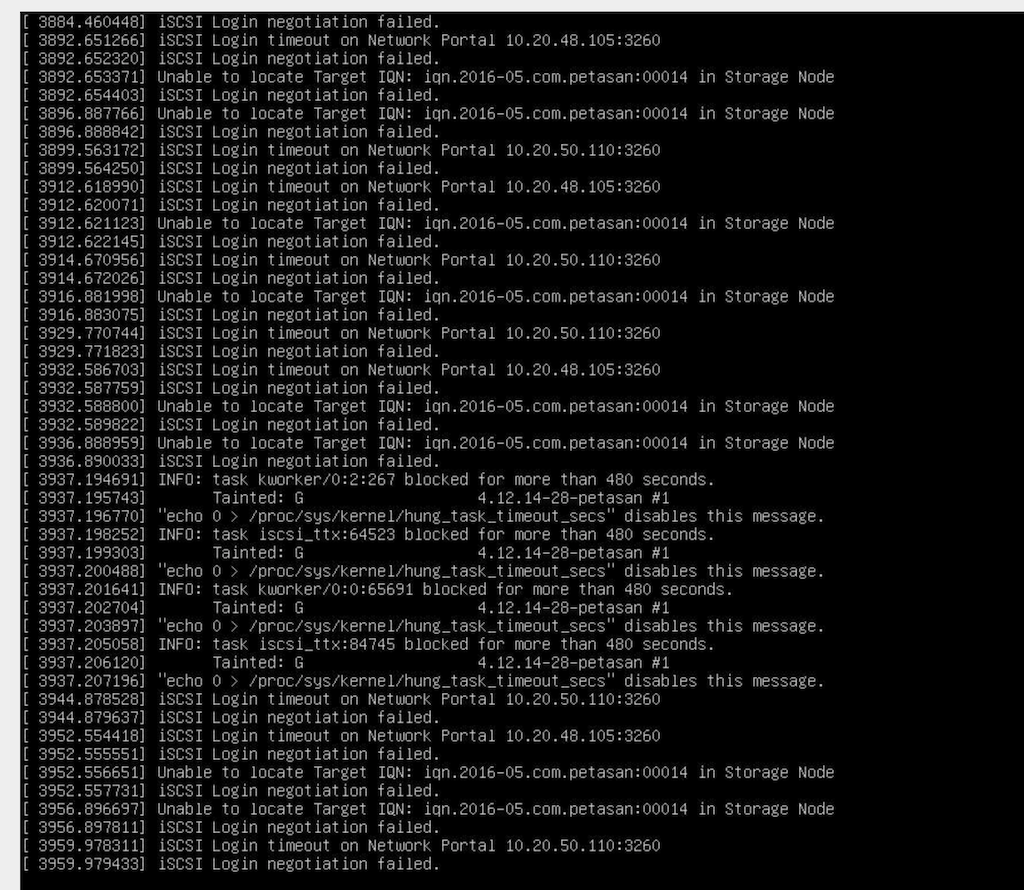
This is from one of the nodes that was actually up.. these messages appear over the blue petasan screen until the screen turns black:
This is some of the items that are showing up in the console of nodes.
This is from a node that is starting up:
This is from one of the nodes that was actually up.. these messages appear over the blue petasan screen until the screen turns black:
neiltorda
99 Posts
July 10, 2022, 4:54 amQuote from neiltorda on July 10, 2022, 4:54 amadding some more info.. I currently have 5 of the six nodes online… this is the output of ceph -s on node1
Every 1.0s: ceph -s petasan1: Sun Jul 10 00:52:46 2022
cluster:
id: 1da111ec-ffe8-4029-9834-e0988079925b
health: HEALTH_WARN
1 filesystem is degraded
insufficient standby MDS daemons available
1 MDSs report slow metadata IOs
1/3 mons down, quorum petasan3,petasan1
Reduced data availability: 698 pgs inactive, 698 pgs down
Degraded data redundancy: 23734388/111928270 objects degraded (21.205%), 1317 pgs degraded, 1321 pgs undersized
services:
mon: 3 daemons, quorum petasan3,petasan1 (age 11m), out of quorum: petasan2
mgr: petasan1(active, since 63m), standbys: petasan3
mds: cephfs:1/1 {0=petasan3=up:replay}
osd: 162 osds: 107 up (since 11m), 107 in (since 103s); 1320 remapped pgs
data:
pools: 5 pools, 3457 pgs
objects: 55.96M objects, 212 TiB
usage: 308 TiB used, 472 TiB / 780 TiB avail
pgs: 20.191% pgs not active
23734388/111928270 objects degraded (21.205%)
1408 active+clean
1200 active+undersized+degraded+remapped+backfill_wait
698 down
67 active+undersized+degraded+remapped+backfilling
50 active+recovery_wait+undersized+degraded+remapped
19 active+clean+scrubbing
11 active+clean+scrubbing+deep
4 active+recovering+undersized+remapped
io:
recovery: 55 MiB/s, 21 objects/s
progress:
Rebalancing after osd.111 marked in (10m)
[==========..................] (remaining: 19m)
Rebalancing after osd.112 marked in (10m)
[========....................] (remaining: 23m)
Rebalancing after osd.90 marked in (11m)
[=========...................] (remaining: 23m)
Rebalancing after osd.120 marked in (10m)
[=========...................] (remaining: 22m)
adding some more info.. I currently have 5 of the six nodes online… this is the output of ceph -s on node1
Every 1.0s: ceph -s petasan1: Sun Jul 10 00:52:46 2022
cluster:
id: 1da111ec-ffe8-4029-9834-e0988079925b
health: HEALTH_WARN
1 filesystem is degraded
insufficient standby MDS daemons available
1 MDSs report slow metadata IOs
1/3 mons down, quorum petasan3,petasan1
Reduced data availability: 698 pgs inactive, 698 pgs down
Degraded data redundancy: 23734388/111928270 objects degraded (21.205%), 1317 pgs degraded, 1321 pgs undersized
services:
mon: 3 daemons, quorum petasan3,petasan1 (age 11m), out of quorum: petasan2
mgr: petasan1(active, since 63m), standbys: petasan3
mds: cephfs:1/1 {0=petasan3=up:replay}
osd: 162 osds: 107 up (since 11m), 107 in (since 103s); 1320 remapped pgs
data:
pools: 5 pools, 3457 pgs
objects: 55.96M objects, 212 TiB
usage: 308 TiB used, 472 TiB / 780 TiB avail
pgs: 20.191% pgs not active
23734388/111928270 objects degraded (21.205%)
1408 active+clean
1200 active+undersized+degraded+remapped+backfill_wait
698 down
67 active+undersized+degraded+remapped+backfilling
50 active+recovery_wait+undersized+degraded+remapped
19 active+clean+scrubbing
11 active+clean+scrubbing+deep
4 active+recovering+undersized+remapped
io:
recovery: 55 MiB/s, 21 objects/s
progress:
Rebalancing after osd.111 marked in (10m)
[==========..................] (remaining: 19m)
Rebalancing after osd.112 marked in (10m)
[========....................] (remaining: 23m)
Rebalancing after osd.90 marked in (11m)
[=========...................] (remaining: 23m)
Rebalancing after osd.120 marked in (10m)
[=========...................] (remaining: 22m)

admin
2,964 Posts
July 10, 2022, 9:17 amQuote from admin on July 10, 2022, 9:17 amTry to lower the recovery backfill speed from the maintenance page to slow. If you have hdds, a lot of recovery load can stress them and make them flap. Also turn off fencing.
Try to lower the recovery backfill speed from the maintenance page to slow. If you have hdds, a lot of recovery load can stress them and make them flap. Also turn off fencing.
neiltorda
99 Posts
July 10, 2022, 12:22 pmQuote from neiltorda on July 10, 2022, 12:22 pmI have turned off fencing. backfill speed was already at slow. I have turned it down to very slow.
I still haven't tried to restart the last node.
The web interface is also not fully functional. The graphs on the dashboard won't load with a 502 bad gateway error.
other screens just won't load at all with a server error.
Should I try to restart the last node again?
I have turned off fencing. backfill speed was already at slow. I have turned it down to very slow.
I still haven't tried to restart the last node.
The web interface is also not fully functional. The graphs on the dashboard won't load with a 502 bad gateway error.
other screens just won't load at all with a server error.
Should I try to restart the last node again?
Last edited on July 10, 2022, 1:43 pm by neiltorda · #5
admin
2,964 Posts
July 10, 2022, 2:31 pmQuote from admin on July 10, 2022, 2:31 pmtry to manually start down osds. if they fail, look at their logs.
try to run atop and see what resources are maxed out
look at the syslog file for any errors
try to manually start down osds. if they fail, look at their logs.
try to run atop and see what resources are maxed out
look at the syslog file for any errors
neiltorda
99 Posts
July 10, 2022, 2:48 pmQuote from neiltorda on July 10, 2022, 2:48 pmI powered on node2 and this time everything stayed up. All my pools are now showing active, but i notice I still have 27 OSD's offline. They are all from node4.
I might try to reboot node 4.
Can you explain what the 'fencing' is? Why did you recommend turning that off?
I powered on node2 and this time everything stayed up. All my pools are now showing active, but i notice I still have 27 OSD's offline. They are all from node4.
I might try to reboot node 4.
Can you explain what the 'fencing' is? Why did you recommend turning that off?
neiltorda
99 Posts
July 10, 2022, 3:12 pmQuote from neiltorda on July 10, 2022, 3:12 pmSorry.. just saw your previous comment (I hadn't reloaded the page before posting my last message)
I rebooted node4, but all of its disks were still marked as down. so I was going to do what you recommended above. I started by getting a list of the OSD's on that node by doing ceph osd tree. As I was getting ready to start trying to start individual disks, they all (except for one) came back online. The one that is down was actually down before all this started and I was planning on replacing it this weekend before everything went crazy.
So, should I turn fencing back on?
This is one of our patch weekend outages, where we do major maintenance to all the university systems. This is what caused the network outage that occurred yesterday.
I was going to upgrade the petasan cluster to the newest version but have not started that process yet.
My current question is this:
should I turn fencing back on
Should I proceed with updating the system the latest version? I am currently running: Version 3.0.2-45drives1
Should fencing be on before I run the updates one node at a time?
I am also still getting a 502 Bad Gateway on the petasan web interface.
Thanks!
Neil
Sorry.. just saw your previous comment (I hadn't reloaded the page before posting my last message)
I rebooted node4, but all of its disks were still marked as down. so I was going to do what you recommended above. I started by getting a list of the OSD's on that node by doing ceph osd tree. As I was getting ready to start trying to start individual disks, they all (except for one) came back online. The one that is down was actually down before all this started and I was planning on replacing it this weekend before everything went crazy.
So, should I turn fencing back on?
This is one of our patch weekend outages, where we do major maintenance to all the university systems. This is what caused the network outage that occurred yesterday.
I was going to upgrade the petasan cluster to the newest version but have not started that process yet.
My current question is this:
should I turn fencing back on
Should I proceed with updating the system the latest version? I am currently running: Version 3.0.2-45drives1
Should fencing be on before I run the updates one node at a time?
I am also still getting a 502 Bad Gateway on the petasan web interface.
Thanks!
Neil
admin
2,964 Posts
July 10, 2022, 5:26 pmQuote from admin on July 10, 2022, 5:26 pmYou can return fencing to on after cluster health is ok, no need for now. Fencing is a function added to iSCSI so in case of failover, the destination node kills the source node to make sure all resources are cleaned, ie to make sure the source node is not half dead.
For the updates, make sure
/etc/apt/sources.list
change the # PetaSAN updates line to
deb http://archive.petasan.org/repo_v3/ petasan-v3 updates
When things stabilize, you may want to custom increase the recovery speed, as the "very slow" entry will probably take foreover and yet the slow entry may be too fast for your current cluster state, so recommend you enter custom speed in steps, still from the same backfill ui page.
If after cluster becomes ok, you still have ui gateway error, look at the PetaSAN.log and syslog for errors.
You can return fencing to on after cluster health is ok, no need for now. Fencing is a function added to iSCSI so in case of failover, the destination node kills the source node to make sure all resources are cleaned, ie to make sure the source node is not half dead.
For the updates, make sure
/etc/apt/sources.list
change the # PetaSAN updates line to
deb http://archive.petasan.org/repo_v3/ petasan-v3 updates
When things stabilize, you may want to custom increase the recovery speed, as the "very slow" entry will probably take foreover and yet the slow entry may be too fast for your current cluster state, so recommend you enter custom speed in steps, still from the same backfill ui page.
If after cluster becomes ok, you still have ui gateway error, look at the PetaSAN.log and syslog for errors.
neiltorda
99 Posts
July 10, 2022, 5:58 pmQuote from neiltorda on July 10, 2022, 5:58 pmso I don't need to stay on the 45drives version of petasan?
Thanks,
Neil
so I don't need to stay on the 45drives version of petasan?
Thanks,
Neil
Pages: 1 2
NODES POWERING OFF AT RANDOM
neiltorda
99 Posts
Quote from neiltorda on July 10, 2022, 3:20 amWe had a major network outage at our site today, where half of our network went offline. 3 of our 6 nodes went offline so we shut everything down until the network could be restored.
I have been trying to get the petasan system back online, but as some nodes come up, others go offline.
The most I have been able to get online at any one time is 5. As soon as the sixth one comes online, various others (sometimes 1, sometimes 2 and at other times 3) nodes will just power off.
The Node list will at times show all 6 nodes being online, when i know for a fact some of the nodes are physically powered down.
The pools will not all come back online and no data can be served.
Any idea what steps should be taken to get the system stable and back up?
Thanks
Neil
We had a major network outage at our site today, where half of our network went offline. 3 of our 6 nodes went offline so we shut everything down until the network could be restored.
I have been trying to get the petasan system back online, but as some nodes come up, others go offline.
The most I have been able to get online at any one time is 5. As soon as the sixth one comes online, various others (sometimes 1, sometimes 2 and at other times 3) nodes will just power off.
The Node list will at times show all 6 nodes being online, when i know for a fact some of the nodes are physically powered down.
The pools will not all come back online and no data can be served.
Any idea what steps should be taken to get the system stable and back up?
Thanks
Neil
neiltorda
99 Posts
Quote from neiltorda on July 10, 2022, 3:34 amThis is some of the items that are showing up in the console of nodes.
This is from a node that is starting up:
This is from one of the nodes that was actually up.. these messages appear over the blue petasan screen until the screen turns black:
This is some of the items that are showing up in the console of nodes.
This is from a node that is starting up:
This is from one of the nodes that was actually up.. these messages appear over the blue petasan screen until the screen turns black:
neiltorda
99 Posts
Quote from neiltorda on July 10, 2022, 4:54 amadding some more info.. I currently have 5 of the six nodes online… this is the output of ceph -s on node1
Every 1.0s: ceph -s petasan1: Sun Jul 10 00:52:46 2022
cluster:
id: 1da111ec-ffe8-4029-9834-e0988079925b
health: HEALTH_WARN
1 filesystem is degraded
insufficient standby MDS daemons available
1 MDSs report slow metadata IOs
1/3 mons down, quorum petasan3,petasan1
Reduced data availability: 698 pgs inactive, 698 pgs down
Degraded data redundancy: 23734388/111928270 objects degraded (21.205%), 1317 pgs degraded, 1321 pgs undersized
services:
mon: 3 daemons, quorum petasan3,petasan1 (age 11m), out of quorum: petasan2
mgr: petasan1(active, since 63m), standbys: petasan3
mds: cephfs:1/1 {0=petasan3=up:replay}
osd: 162 osds: 107 up (since 11m), 107 in (since 103s); 1320 remapped pgs
data:
pools: 5 pools, 3457 pgs
objects: 55.96M objects, 212 TiB
usage: 308 TiB used, 472 TiB / 780 TiB avail
pgs: 20.191% pgs not active
23734388/111928270 objects degraded (21.205%)
1408 active+clean
1200 active+undersized+degraded+remapped+backfill_wait
698 down
67 active+undersized+degraded+remapped+backfilling
50 active+recovery_wait+undersized+degraded+remapped
19 active+clean+scrubbing
11 active+clean+scrubbing+deep
4 active+recovering+undersized+remapped
io:
recovery: 55 MiB/s, 21 objects/s
progress:
Rebalancing after osd.111 marked in (10m)
[==========..................] (remaining: 19m)
Rebalancing after osd.112 marked in (10m)
[========....................] (remaining: 23m)
Rebalancing after osd.90 marked in (11m)
[=========...................] (remaining: 23m)
Rebalancing after osd.120 marked in (10m)
[=========...................] (remaining: 22m)
adding some more info.. I currently have 5 of the six nodes online… this is the output of ceph -s on node1
Every 1.0s: ceph -s petasan1: Sun Jul 10 00:52:46 2022
cluster:
id: 1da111ec-ffe8-4029-9834-e0988079925b
health: HEALTH_WARN
1 filesystem is degraded
insufficient standby MDS daemons available
1 MDSs report slow metadata IOs
1/3 mons down, quorum petasan3,petasan1
Reduced data availability: 698 pgs inactive, 698 pgs down
Degraded data redundancy: 23734388/111928270 objects degraded (21.205%), 1317 pgs degraded, 1321 pgs undersized
services:
mon: 3 daemons, quorum petasan3,petasan1 (age 11m), out of quorum: petasan2
mgr: petasan1(active, since 63m), standbys: petasan3
mds: cephfs:1/1 {0=petasan3=up:replay}
osd: 162 osds: 107 up (since 11m), 107 in (since 103s); 1320 remapped pgs
data:
pools: 5 pools, 3457 pgs
objects: 55.96M objects, 212 TiB
usage: 308 TiB used, 472 TiB / 780 TiB avail
pgs: 20.191% pgs not active
23734388/111928270 objects degraded (21.205%)
1408 active+clean
1200 active+undersized+degraded+remapped+backfill_wait
698 down
67 active+undersized+degraded+remapped+backfilling
50 active+recovery_wait+undersized+degraded+remapped
19 active+clean+scrubbing
11 active+clean+scrubbing+deep
4 active+recovering+undersized+remapped
io:
recovery: 55 MiB/s, 21 objects/s
progress:
Rebalancing after osd.111 marked in (10m)
[==========..................] (remaining: 19m)
Rebalancing after osd.112 marked in (10m)
[========....................] (remaining: 23m)
Rebalancing after osd.90 marked in (11m)
[=========...................] (remaining: 23m)
Rebalancing after osd.120 marked in (10m)
[=========...................] (remaining: 22m)
admin
2,964 Posts
Quote from admin on July 10, 2022, 9:17 amTry to lower the recovery backfill speed from the maintenance page to slow. If you have hdds, a lot of recovery load can stress them and make them flap. Also turn off fencing.
Try to lower the recovery backfill speed from the maintenance page to slow. If you have hdds, a lot of recovery load can stress them and make them flap. Also turn off fencing.
neiltorda
99 Posts
Quote from neiltorda on July 10, 2022, 12:22 pmI have turned off fencing. backfill speed was already at slow. I have turned it down to very slow.
I still haven't tried to restart the last node.
The web interface is also not fully functional. The graphs on the dashboard won't load with a 502 bad gateway error.
other screens just won't load at all with a server error.
Should I try to restart the last node again?
I have turned off fencing. backfill speed was already at slow. I have turned it down to very slow.
I still haven't tried to restart the last node.
The web interface is also not fully functional. The graphs on the dashboard won't load with a 502 bad gateway error.
other screens just won't load at all with a server error.
Should I try to restart the last node again?
admin
2,964 Posts
Quote from admin on July 10, 2022, 2:31 pmtry to manually start down osds. if they fail, look at their logs.
try to run atop and see what resources are maxed out
look at the syslog file for any errors
try to manually start down osds. if they fail, look at their logs.
try to run atop and see what resources are maxed out
look at the syslog file for any errors
neiltorda
99 Posts
Quote from neiltorda on July 10, 2022, 2:48 pmI powered on node2 and this time everything stayed up. All my pools are now showing active, but i notice I still have 27 OSD's offline. They are all from node4.
I might try to reboot node 4.
Can you explain what the 'fencing' is? Why did you recommend turning that off?
I powered on node2 and this time everything stayed up. All my pools are now showing active, but i notice I still have 27 OSD's offline. They are all from node4.
I might try to reboot node 4.
Can you explain what the 'fencing' is? Why did you recommend turning that off?
neiltorda
99 Posts
Quote from neiltorda on July 10, 2022, 3:12 pmSorry.. just saw your previous comment (I hadn't reloaded the page before posting my last message)
I rebooted node4, but all of its disks were still marked as down. so I was going to do what you recommended above. I started by getting a list of the OSD's on that node by doing ceph osd tree. As I was getting ready to start trying to start individual disks, they all (except for one) came back online. The one that is down was actually down before all this started and I was planning on replacing it this weekend before everything went crazy.
So, should I turn fencing back on?
This is one of our patch weekend outages, where we do major maintenance to all the university systems. This is what caused the network outage that occurred yesterday.
I was going to upgrade the petasan cluster to the newest version but have not started that process yet.
My current question is this:
should I turn fencing back on
Should I proceed with updating the system the latest version? I am currently running: Version 3.0.2-45drives1
Should fencing be on before I run the updates one node at a time?
I am also still getting a 502 Bad Gateway on the petasan web interface.Thanks!
Neil
Sorry.. just saw your previous comment (I hadn't reloaded the page before posting my last message)
I rebooted node4, but all of its disks were still marked as down. so I was going to do what you recommended above. I started by getting a list of the OSD's on that node by doing ceph osd tree. As I was getting ready to start trying to start individual disks, they all (except for one) came back online. The one that is down was actually down before all this started and I was planning on replacing it this weekend before everything went crazy.
So, should I turn fencing back on?
This is one of our patch weekend outages, where we do major maintenance to all the university systems. This is what caused the network outage that occurred yesterday.
I was going to upgrade the petasan cluster to the newest version but have not started that process yet.
My current question is this:
should I turn fencing back on
Should I proceed with updating the system the latest version? I am currently running: Version 3.0.2-45drives1
Should fencing be on before I run the updates one node at a time?
I am also still getting a 502 Bad Gateway on the petasan web interface.
Thanks!
Neil
admin
2,964 Posts
Quote from admin on July 10, 2022, 5:26 pmYou can return fencing to on after cluster health is ok, no need for now. Fencing is a function added to iSCSI so in case of failover, the destination node kills the source node to make sure all resources are cleaned, ie to make sure the source node is not half dead.
For the updates, make sure
/etc/apt/sources.list
change the # PetaSAN updates line to
deb http://archive.petasan.org/repo_v3/ petasan-v3 updatesWhen things stabilize, you may want to custom increase the recovery speed, as the "very slow" entry will probably take foreover and yet the slow entry may be too fast for your current cluster state, so recommend you enter custom speed in steps, still from the same backfill ui page.
If after cluster becomes ok, you still have ui gateway error, look at the PetaSAN.log and syslog for errors.
You can return fencing to on after cluster health is ok, no need for now. Fencing is a function added to iSCSI so in case of failover, the destination node kills the source node to make sure all resources are cleaned, ie to make sure the source node is not half dead.
For the updates, make sure
/etc/apt/sources.list
change the # PetaSAN updates line to
deb http://archive.petasan.org/repo_v3/ petasan-v3 updates
When things stabilize, you may want to custom increase the recovery speed, as the "very slow" entry will probably take foreover and yet the slow entry may be too fast for your current cluster state, so recommend you enter custom speed in steps, still from the same backfill ui page.
If after cluster becomes ok, you still have ui gateway error, look at the PetaSAN.log and syslog for errors.
neiltorda
99 Posts
Quote from neiltorda on July 10, 2022, 5:58 pmso I don't need to stay on the 45drives version of petasan?
Thanks,
Neil
so I don't need to stay on the 45drives version of petasan?
Thanks,
Neil