
iSCSI disk list gone
Pages: 1 2

wailer
75 Posts
October 23, 2020, 6:08 pmQuote from wailer on October 23, 2020, 6:08 pmHi,
After a node failure , cluster in version 2.5.3 status is:
And iscsi disk list is empty, so we are not able to start disks.
We have tried to do, without success
/opt/petasan/scripts/util/start_all_disks.py
Any hint to get disks back to web interface?
Thanks!
LOGS from CEPH-12
23/10/2020 16:54:25 INFO PetaSAN cleaned iqns.
23/10/2020 16:54:25 INFO Image image-00005 unmapped successfully.
23/10/2020 16:54:23 INFO LIO deleted Target iqn.2016-05.com.petasan:00005
23/10/2020 16:54:23 INFO LIO deleted backstore image image-00005
23/10/2020 16:54:22 INFO Image image-00003 unmapped successfully.
23/10/2020 16:54:20 INFO LIO deleted Target iqn.2016-05.com.petasan:00003
23/10/2020 16:54:20 INFO LIO deleted backstore image image-00003
23/10/2020 16:54:19 INFO Image image-00001 unmapped successfully.
23/10/2020 16:54:17 INFO LIO deleted Target iqn.2016-05.com.petasan:00001
23/10/2020 16:54:17 INFO LIO deleted backstore image image-00001
23/10/2020 16:54:15 INFO PetaSAN cleaned local paths not locked by this node in consul.
Hi,
After a node failure , cluster in version 2.5.3 status is:
And iscsi disk list is empty, so we are not able to start disks.
We have tried to do, without success
/opt/petasan/scripts/util/start_all_disks.py
Any hint to get disks back to web interface?
Thanks!
LOGS from CEPH-12
23/10/2020 16:54:25 INFO PetaSAN cleaned iqns.
23/10/2020 16:54:25 INFO Image image-00005 unmapped successfully.
23/10/2020 16:54:23 INFO LIO deleted Target iqn.2016-05.com.petasan:00005
23/10/2020 16:54:23 INFO LIO deleted backstore image image-00005
23/10/2020 16:54:22 INFO Image image-00003 unmapped successfully.
23/10/2020 16:54:20 INFO LIO deleted Target iqn.2016-05.com.petasan:00003
23/10/2020 16:54:20 INFO LIO deleted backstore image image-00003
23/10/2020 16:54:19 INFO Image image-00001 unmapped successfully.
23/10/2020 16:54:17 INFO LIO deleted Target iqn.2016-05.com.petasan:00001
23/10/2020 16:54:17 INFO LIO deleted backstore image image-00001
23/10/2020 16:54:15 INFO PetaSAN cleaned local paths not locked by this node in consul.
Last edited on October 23, 2020, 6:20 pm by wailer · #1

admin
2,930 Posts
October 23, 2020, 10:00 pmQuote from admin on October 23, 2020, 10:00 pmIn the PetaSAN ui, under the Pools List page, do the pools show as active ? If the system is slow (as reported by the slow ops status), some ui operation can timeout after 5 or 10 sec and the ui will show the pool as inactive, it will also not show the iSCSI disks on that pool ( the list of disks is read from its pool, so if it timeout it will not the show the iSCSI disks ).
In case you are getting these timeouts, it could be due to recovery traffic, try to lower the backfill/recovery speed in the Maintenance tab and see it help.
In the PetaSAN ui, under the Pools List page, do the pools show as active ? If the system is slow (as reported by the slow ops status), some ui operation can timeout after 5 or 10 sec and the ui will show the pool as inactive, it will also not show the iSCSI disks on that pool ( the list of disks is read from its pool, so if it timeout it will not the show the iSCSI disks ).
In case you are getting these timeouts, it could be due to recovery traffic, try to lower the backfill/recovery speed in the Maintenance tab and see it help.
wailer
75 Posts
October 24, 2020, 7:11 amQuote from wailer on October 24, 2020, 7:11 amThank you,
The pool shows inactive when you open pools page, then, after about 10 seconds, shows active.
Have tried to slow down recovery traffic as you said, one of the nodes is really loaded. iSCSI disks appear sometimes now...
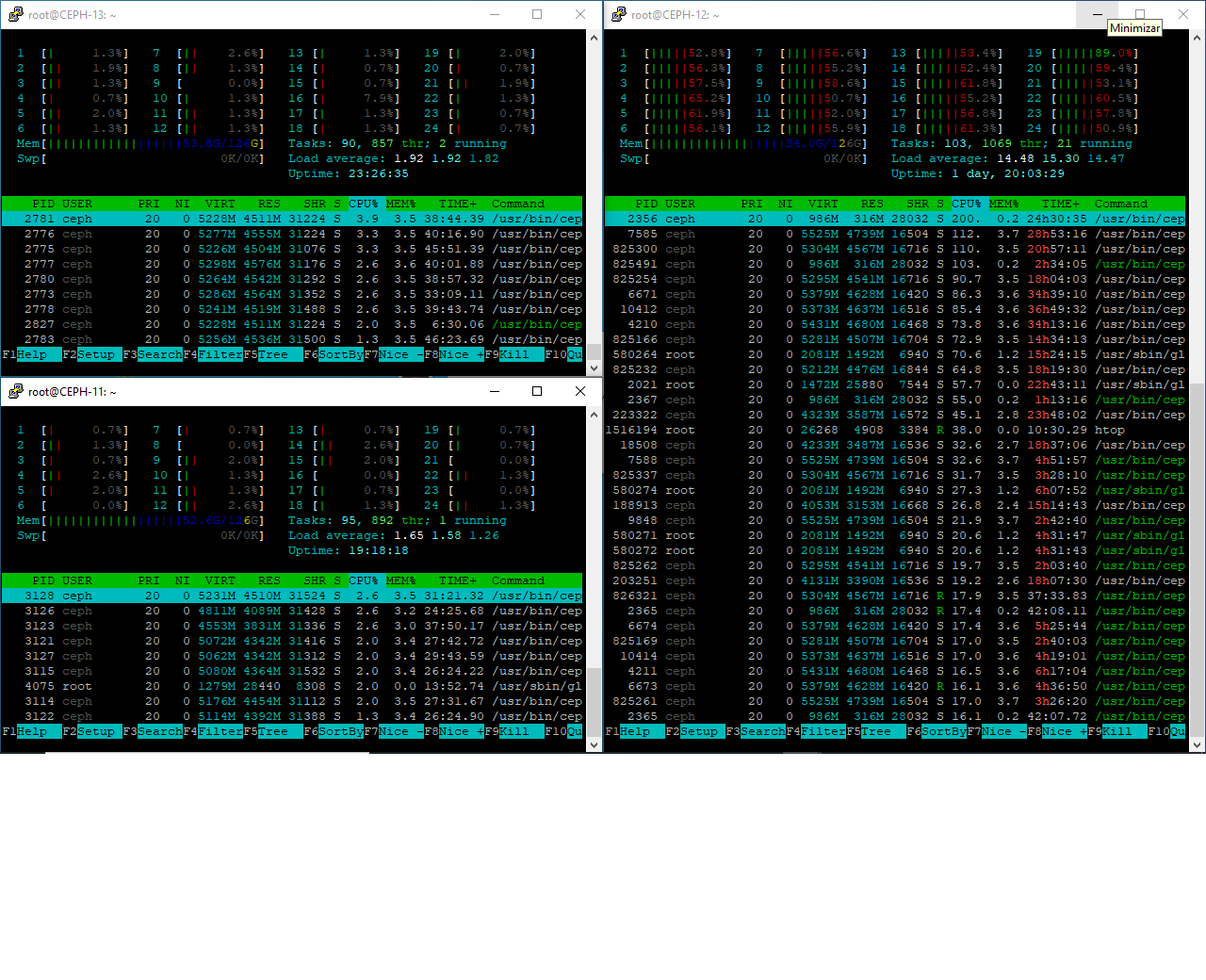
Thank you,
The pool shows inactive when you open pools page, then, after about 10 seconds, shows active.
Have tried to slow down recovery traffic as you said, one of the nodes is really loaded. iSCSI disks appear sometimes now...
Last edited on October 24, 2020, 7:11 am by wailer · #3
admin
2,930 Posts
October 24, 2020, 10:25 amQuote from admin on October 24, 2020, 10:25 amWhat is the status at the ceph layer, do you still get slow ops reported or is it ok ?
What is utilization load bottleneck: cpu, network, disk, ram ?
How many OSD nodes do you have and how many OSDs per node ?
How many iSCSI nodes ?
Can you reduce client load ? can you move paths from loaded node ?
What is the replication level : x3 ?
Is the down node up now ?
What is the status at the ceph layer, do you still get slow ops reported or is it ok ?
What is utilization load bottleneck: cpu, network, disk, ram ?
How many OSD nodes do you have and how many OSDs per node ?
How many iSCSI nodes ?
Can you reduce client load ? can you move paths from loaded node ?
What is the replication level : x3 ?
Is the down node up now ?
Last edited on October 24, 2020, 10:28 am by admin · #4
wailer
75 Posts
October 24, 2020, 5:56 pmQuote from wailer on October 24, 2020, 5:56 pmWhat is the status at the ceph layer, do you still get slow ops reported or is it ok ?
Yes here is ceph health detail:
HEALTH_WARN Degraded data redundancy: 3245122/48212490 objects degraded (6.731%), 227 pgs degraded, 228 pgs undersized; 1 slow ops, oldest one blocked for 10
7925 sec, mon.CEPH-12 has slow ops
PG_DEGRADED Degraded data redundancy: 3245122/48212490 objects degraded (6.731%), 227 pgs degraded, 228 pgs undersized
pg 1.2d5 is active+undersized+degraded+remapped+backfill_wait, acting [18,4]
pg 1.2d6 is stuck undersized for 107951.473880, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,16]
pg 1.2dc is stuck undersized for 107948.162212, current state active+undersized+degraded+remapped+backfill_wait, last acting [5,21]
pg 1.2dd is stuck undersized for 107948.129835, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,17]
pg 1.2e5 is stuck undersized for 107948.111425, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,23]
pg 1.2ea is stuck undersized for 107948.152514, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,17]
pg 1.2fa is stuck undersized for 107948.155469, current state active+undersized+degraded+remapped+backfill_wait, last acting [3,19]
pg 1.2fc is stuck undersized for 107948.133065, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,16]
pg 1.2fe is stuck undersized for 107948.141732, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,16]
pg 1.304 is stuck undersized for 107943.325286, current state active+undersized+degraded+remapped+backfill_wait, last acting [20,4]
pg 1.308 is stuck undersized for 107948.731479, current state active+undersized+degraded+remapped+backfill_wait, last acting [22,6]
pg 1.30b is stuck undersized for 107951.535692, current state active+undersized+degraded+remapped+backfill_wait, last acting [5,23]
pg 1.313 is stuck undersized for 107948.154676, current state active+undersized+degraded+remapped+backfill_wait, last acting [0,23]
pg 1.317 is stuck undersized for 107946.307538, current state active+undersized+degraded+remapped+backfilling, last acting [17,1]
pg 1.31a is stuck undersized for 107944.287470, current state active+undersized+degraded+remapped+backfill_wait, last acting [23,7]
pg 1.326 is stuck undersized for 107948.107936, current state active+undersized+degraded+remapped+backfill_wait, last acting [7,18]
pg 1.327 is stuck undersized for 107949.852230, current state active+undersized+degraded+remapped+backfill_wait, last acting [17,6]
pg 1.335 is stuck undersized for 107948.113297, current state active+undersized+degraded+remapped+backfill_wait, last acting [3,23]
pg 1.33b is stuck undersized for 107946.692066, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,23]
pg 1.342 is stuck undersized for 107948.159769, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,19]
pg 1.344 is stuck undersized for 107939.597347, current state active+undersized+degraded+remapped+backfill_wait, last acting [22,3]
pg 1.349 is stuck undersized for 107951.489330, current state active+undersized+degraded+remapped+backfill_wait, last acting [2,19]
pg 1.34b is stuck undersized for 107948.159365, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,19]
pg 1.34c is stuck undersized for 107945.134625, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,16]
pg 1.361 is stuck undersized for 107944.853218, current state active+undersized+degraded+remapped+backfill_wait, last acting [23,5]
pg 1.363 is stuck undersized for 107947.639559, current state active+undersized+degraded+remapped+backfill_wait, last acting [18,6]
pg 1.364 is stuck undersized for 107950.079675, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,19]
pg 1.372 is stuck undersized for 107948.623616, current state active+undersized+degraded+remapped+backfill_wait, last acting [16,3]
pg 1.379 is stuck undersized for 107941.358181, current state active+undersized+degraded+remapped+backfill_wait, last acting [2,20]
pg 1.37a is stuck undersized for 107945.135502, current state active+undersized+degraded+remapped+backfill_wait, last acting [7,19]
pg 1.37b is stuck undersized for 107945.135058, current state active+undersized+degraded+remapped+backfill_wait, last acting [0,22]
pg 1.383 is stuck undersized for 107946.003141, current state active+undersized+degraded+remapped+backfill_wait, last acting [16,7]
pg 1.397 is stuck undersized for 107943.956306, current state active+undersized+degraded+remapped+backfill_wait, last acting [18,2]
pg 1.3a6 is stuck undersized for 107950.878611, current state active+undersized+degraded+remapped+backfill_wait, last acting [18,7]
pg 1.3a9 is stuck undersized for 107944.678313, current state active+undersized+degraded+remapped+backfill_wait, last acting [22,0]
pg 1.3b0 is stuck undersized for 107945.297371, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,18]
pg 1.3b3 is stuck undersized for 107948.135891, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,17]
pg 1.3bc is stuck undersized for 107946.695125, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,18]
pg 1.3be is stuck undersized for 107951.502614, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,18]
pg 1.3c0 is stuck undersized for 107947.195574, current state active+undersized+degraded+remapped+backfill_wait, last acting [18,6]
pg 1.3c1 is stuck undersized for 107948.160991, current state active+undersized+degraded+remapped+backfill_wait, last acting [7,21]
pg 1.3c4 is stuck undersized for 107948.135944, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,19]
pg 1.3c5 is stuck undersized for 107943.564031, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,22]
pg 1.3cd is stuck undersized for 107944.929907, current state active+undersized+degraded+remapped+backfill_wait, last acting [17,3]
...
...
What is utilization load bottleneck: cpu, network, disk, ram ?
CPU at node 2. When I slow down backfilling, CPU load is somehow reduced too, at this node.
How many OSD nodes do you have and how many OSDs per node ?
36 OSD's (10TB disks) - 12 OSD's per node
OS disk is 480GB enterprise SSD (RAID1)
How many iSCSI nodes ?
All 3 nodes hold iscsi role
Can you reduce client load ?
I reduced it all I could right now
can you move paths from loaded node ?
I am unable to access path config page to move them , graphs / UI are currently misbehaving with timeouts.
What is the replication level : x3 ?
Yes it's x3
Is the down node up now ?
Yes all nodes are up.
Thanks!
What is the status at the ceph layer, do you still get slow ops reported or is it ok ?
Yes here is ceph health detail:
HEALTH_WARN Degraded data redundancy: 3245122/48212490 objects degraded (6.731%), 227 pgs degraded, 228 pgs undersized; 1 slow ops, oldest one blocked for 10
7925 sec, mon.CEPH-12 has slow ops
PG_DEGRADED Degraded data redundancy: 3245122/48212490 objects degraded (6.731%), 227 pgs degraded, 228 pgs undersized
pg 1.2d5 is active+undersized+degraded+remapped+backfill_wait, acting [18,4]
pg 1.2d6 is stuck undersized for 107951.473880, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,16]
pg 1.2dc is stuck undersized for 107948.162212, current state active+undersized+degraded+remapped+backfill_wait, last acting [5,21]
pg 1.2dd is stuck undersized for 107948.129835, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,17]
pg 1.2e5 is stuck undersized for 107948.111425, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,23]
pg 1.2ea is stuck undersized for 107948.152514, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,17]
pg 1.2fa is stuck undersized for 107948.155469, current state active+undersized+degraded+remapped+backfill_wait, last acting [3,19]
pg 1.2fc is stuck undersized for 107948.133065, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,16]
pg 1.2fe is stuck undersized for 107948.141732, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,16]
pg 1.304 is stuck undersized for 107943.325286, current state active+undersized+degraded+remapped+backfill_wait, last acting [20,4]
pg 1.308 is stuck undersized for 107948.731479, current state active+undersized+degraded+remapped+backfill_wait, last acting [22,6]
pg 1.30b is stuck undersized for 107951.535692, current state active+undersized+degraded+remapped+backfill_wait, last acting [5,23]
pg 1.313 is stuck undersized for 107948.154676, current state active+undersized+degraded+remapped+backfill_wait, last acting [0,23]
pg 1.317 is stuck undersized for 107946.307538, current state active+undersized+degraded+remapped+backfilling, last acting [17,1]
pg 1.31a is stuck undersized for 107944.287470, current state active+undersized+degraded+remapped+backfill_wait, last acting [23,7]
pg 1.326 is stuck undersized for 107948.107936, current state active+undersized+degraded+remapped+backfill_wait, last acting [7,18]
pg 1.327 is stuck undersized for 107949.852230, current state active+undersized+degraded+remapped+backfill_wait, last acting [17,6]
pg 1.335 is stuck undersized for 107948.113297, current state active+undersized+degraded+remapped+backfill_wait, last acting [3,23]
pg 1.33b is stuck undersized for 107946.692066, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,23]
pg 1.342 is stuck undersized for 107948.159769, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,19]
pg 1.344 is stuck undersized for 107939.597347, current state active+undersized+degraded+remapped+backfill_wait, last acting [22,3]
pg 1.349 is stuck undersized for 107951.489330, current state active+undersized+degraded+remapped+backfill_wait, last acting [2,19]
pg 1.34b is stuck undersized for 107948.159365, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,19]
pg 1.34c is stuck undersized for 107945.134625, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,16]
pg 1.361 is stuck undersized for 107944.853218, current state active+undersized+degraded+remapped+backfill_wait, last acting [23,5]
pg 1.363 is stuck undersized for 107947.639559, current state active+undersized+degraded+remapped+backfill_wait, last acting [18,6]
pg 1.364 is stuck undersized for 107950.079675, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,19]
pg 1.372 is stuck undersized for 107948.623616, current state active+undersized+degraded+remapped+backfill_wait, last acting [16,3]
pg 1.379 is stuck undersized for 107941.358181, current state active+undersized+degraded+remapped+backfill_wait, last acting [2,20]
pg 1.37a is stuck undersized for 107945.135502, current state active+undersized+degraded+remapped+backfill_wait, last acting [7,19]
pg 1.37b is stuck undersized for 107945.135058, current state active+undersized+degraded+remapped+backfill_wait, last acting [0,22]
pg 1.383 is stuck undersized for 107946.003141, current state active+undersized+degraded+remapped+backfill_wait, last acting [16,7]
pg 1.397 is stuck undersized for 107943.956306, current state active+undersized+degraded+remapped+backfill_wait, last acting [18,2]
pg 1.3a6 is stuck undersized for 107950.878611, current state active+undersized+degraded+remapped+backfill_wait, last acting [18,7]
pg 1.3a9 is stuck undersized for 107944.678313, current state active+undersized+degraded+remapped+backfill_wait, last acting [22,0]
pg 1.3b0 is stuck undersized for 107945.297371, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,18]
pg 1.3b3 is stuck undersized for 107948.135891, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,17]
pg 1.3bc is stuck undersized for 107946.695125, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,18]
pg 1.3be is stuck undersized for 107951.502614, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,18]
pg 1.3c0 is stuck undersized for 107947.195574, current state active+undersized+degraded+remapped+backfill_wait, last acting [18,6]
pg 1.3c1 is stuck undersized for 107948.160991, current state active+undersized+degraded+remapped+backfill_wait, last acting [7,21]
pg 1.3c4 is stuck undersized for 107948.135944, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,19]
pg 1.3c5 is stuck undersized for 107943.564031, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,22]
pg 1.3cd is stuck undersized for 107944.929907, current state active+undersized+degraded+remapped+backfill_wait, last acting [17,3]
...
...
What is utilization load bottleneck: cpu, network, disk, ram ?
CPU at node 2. When I slow down backfilling, CPU load is somehow reduced too, at this node.
How many OSD nodes do you have and how many OSDs per node ?
36 OSD's (10TB disks) - 12 OSD's per node
OS disk is 480GB enterprise SSD (RAID1)
How many iSCSI nodes ?
All 3 nodes hold iscsi role
Can you reduce client load ?
I reduced it all I could right now
can you move paths from loaded node ?
I am unable to access path config page to move them , graphs / UI are currently misbehaving with timeouts.
What is the replication level : x3 ?
Yes it's x3
Is the down node up now ?
Yes all nodes are up.
Thanks!
admin
2,930 Posts
October 25, 2020, 9:45 amQuote from admin on October 25, 2020, 9:45 amyou should lower the load, either client load or recovery load. Monitor the Ceph status as well as the PG Status chart to make sure Ceph is recovering and not stuck.
you should lower the load, either client load or recovery load. Monitor the Ceph status as well as the PG Status chart to make sure Ceph is recovering and not stuck.
wailer
75 Posts
October 25, 2020, 7:31 pmQuote from wailer on October 25, 2020, 7:31 pmThank you, I set backfill speed to very slow, I will wait until the cluster finishes restoring, I guess it will take some days...as it looks to be working, just slowly..(around 40 pg's per day)
Thank you, I set backfill speed to very slow, I will wait until the cluster finishes restoring, I guess it will take some days...as it looks to be working, just slowly..(around 40 pg's per day)
Last edited on October 25, 2020, 7:32 pm by wailer · #7
wailer
75 Posts
October 27, 2020, 9:08 amQuote from wailer on October 27, 2020, 9:08 amHi again,
Seems that backfilling has finished, but UI is still not working correctly. Also graphs are giving bad gateway error.
Current cluster status is:
Affected node is still having extremely high CPU load. How can I find or unstuck this slow op?
Thanks!
EDIT: Checking ceph logs, looks like there's some recovery tasks going on yet:
2020-10-27 10:51:50.537092 mgr.CEPH-12 (mgr.22689265) 113372 : cluster [DBG] pgmap v101792: 1024 pgs: 2 active+clean+scrubbing+deep, 2 active+remapped+backfilling, 39 active+remapped+backfill_wait, 981 active+clean; 55 TiB data, 152 TiB used, 176 TiB / 327 TiB avail; 13 MiB/s rd, 26 MiB/s wr, 299 op/s; 631567/48321099 objects misplaced (1.307%); 22 MiB/s, 6 objects/s recovering.
Maybe this is the reason of the high load?
Hi again,
Seems that backfilling has finished, but UI is still not working correctly. Also graphs are giving bad gateway error.
Current cluster status is:
Affected node is still having extremely high CPU load. How can I find or unstuck this slow op?
Thanks!
EDIT: Checking ceph logs, looks like there's some recovery tasks going on yet:
2020-10-27 10:51:50.537092 mgr.CEPH-12 (mgr.22689265) 113372 : cluster [DBG] pgmap v101792: 1024 pgs: 2 active+clean+scrubbing+deep, 2 active+remapped+backfilling, 39 active+remapped+backfill_wait, 981 active+clean; 55 TiB data, 152 TiB used, 176 TiB / 327 TiB avail; 13 MiB/s rd, 26 MiB/s wr, 299 op/s; 631567/48321099 objects misplaced (1.307%); 22 MiB/s, 6 objects/s recovering.
Maybe this is the reason of the high load?
Last edited on October 27, 2020, 9:53 am by wailer · #8
admin
2,930 Posts
October 27, 2020, 1:43 pmQuote from admin on October 27, 2020, 1:43 pmdoes ceph status show you all pgs clean or does it show backfill recovery ?
does ceph status show you all pgs clean or does it show backfill recovery ?
wailer
75 Posts
October 27, 2020, 6:16 pmQuote from wailer on October 27, 2020, 6:16 pmLooks like all backfills have finished now, the load on this node is still persisting, also the slow op reported.
root@CEPH-12:~# ceph health
HEALTH_WARN 126 pgs not scrubbed in time; 1 slow ops, oldest one blocked for 368671 sec, mon.CEPH-12 has slow ops
root@CEPH-12:~# ceph -s
cluster:
id: 5e2d37a0-a9ca-4ebf-814d-892d1da42032
health: HEALTH_WARN
128 pgs not scrubbed in time
1 slow ops, oldest one blocked for 368545 sec, mon.CEPH-12 has slow ops
services:
mon: 3 daemons, quorum CEPH-13,CEPH-11,CEPH-12 (age 4d)
mgr: CEPH-12(active, since 4d), standbys: CEPH-13, CEPH-11
osd: 36 osds: 36 up (since 4d), 36 in (since 4d)
data:
pools: 1 pools, 1024 pgs
objects: 16.10M objects, 55 TiB
usage: 151 TiB used, 176 TiB / 327 TiB avail
pgs: 1014 active+clean
6 active+clean+scrubbing+deep
4 active+clean+scrubbing
io:
client: 15 MiB/s rd, 9.8 MiB/s wr, 104 op/s rd, 63 op/s wr
Thanks!
Looks like all backfills have finished now, the load on this node is still persisting, also the slow op reported.
root@CEPH-12:~# ceph health
HEALTH_WARN 126 pgs not scrubbed in time; 1 slow ops, oldest one blocked for 368671 sec, mon.CEPH-12 has slow ops
root@CEPH-12:~# ceph -s
cluster:
id: 5e2d37a0-a9ca-4ebf-814d-892d1da42032
health: HEALTH_WARN
128 pgs not scrubbed in time
1 slow ops, oldest one blocked for 368545 sec, mon.CEPH-12 has slow ops
services:
mon: 3 daemons, quorum CEPH-13,CEPH-11,CEPH-12 (age 4d)
mgr: CEPH-12(active, since 4d), standbys: CEPH-13, CEPH-11
osd: 36 osds: 36 up (since 4d), 36 in (since 4d)
data:
pools: 1 pools, 1024 pgs
objects: 16.10M objects, 55 TiB
usage: 151 TiB used, 176 TiB / 327 TiB avail
pgs: 1014 active+clean
6 active+clean+scrubbing+deep
4 active+clean+scrubbing
io:
client: 15 MiB/s rd, 9.8 MiB/s wr, 104 op/s rd, 63 op/s wr
Thanks!
Pages: 1 2
iSCSI disk list gone
wailer
75 Posts
Quote from wailer on October 23, 2020, 6:08 pmHi,
After a node failure , cluster in version 2.5.3 status is:
And iscsi disk list is empty, so we are not able to start disks.
We have tried to do, without success
/opt/petasan/scripts/util/start_all_disks.py
Any hint to get disks back to web interface?
Thanks!
LOGS from CEPH-12
23/10/2020 16:54:25 INFO PetaSAN cleaned iqns.
23/10/2020 16:54:25 INFO Image image-00005 unmapped successfully.
23/10/2020 16:54:23 INFO LIO deleted Target iqn.2016-05.com.petasan:00005
23/10/2020 16:54:23 INFO LIO deleted backstore image image-00005
23/10/2020 16:54:22 INFO Image image-00003 unmapped successfully.
23/10/2020 16:54:20 INFO LIO deleted Target iqn.2016-05.com.petasan:00003
23/10/2020 16:54:20 INFO LIO deleted backstore image image-00003
23/10/2020 16:54:19 INFO Image image-00001 unmapped successfully.
23/10/2020 16:54:17 INFO LIO deleted Target iqn.2016-05.com.petasan:00001
23/10/2020 16:54:17 INFO LIO deleted backstore image image-00001
23/10/2020 16:54:15 INFO PetaSAN cleaned local paths not locked by this node in consul.
Hi,
After a node failure , cluster in version 2.5.3 status is:
And iscsi disk list is empty, so we are not able to start disks.
We have tried to do, without success
/opt/petasan/scripts/util/start_all_disks.py
Any hint to get disks back to web interface?
Thanks!
LOGS from CEPH-12
23/10/2020 16:54:25 INFO PetaSAN cleaned iqns.
23/10/2020 16:54:25 INFO Image image-00005 unmapped successfully.
23/10/2020 16:54:23 INFO LIO deleted Target iqn.2016-05.com.petasan:00005
23/10/2020 16:54:23 INFO LIO deleted backstore image image-00005
23/10/2020 16:54:22 INFO Image image-00003 unmapped successfully.
23/10/2020 16:54:20 INFO LIO deleted Target iqn.2016-05.com.petasan:00003
23/10/2020 16:54:20 INFO LIO deleted backstore image image-00003
23/10/2020 16:54:19 INFO Image image-00001 unmapped successfully.
23/10/2020 16:54:17 INFO LIO deleted Target iqn.2016-05.com.petasan:00001
23/10/2020 16:54:17 INFO LIO deleted backstore image image-00001
23/10/2020 16:54:15 INFO PetaSAN cleaned local paths not locked by this node in consul.
admin
2,930 Posts
Quote from admin on October 23, 2020, 10:00 pmIn the PetaSAN ui, under the Pools List page, do the pools show as active ? If the system is slow (as reported by the slow ops status), some ui operation can timeout after 5 or 10 sec and the ui will show the pool as inactive, it will also not show the iSCSI disks on that pool ( the list of disks is read from its pool, so if it timeout it will not the show the iSCSI disks ).
In case you are getting these timeouts, it could be due to recovery traffic, try to lower the backfill/recovery speed in the Maintenance tab and see it help.
In the PetaSAN ui, under the Pools List page, do the pools show as active ? If the system is slow (as reported by the slow ops status), some ui operation can timeout after 5 or 10 sec and the ui will show the pool as inactive, it will also not show the iSCSI disks on that pool ( the list of disks is read from its pool, so if it timeout it will not the show the iSCSI disks ).
In case you are getting these timeouts, it could be due to recovery traffic, try to lower the backfill/recovery speed in the Maintenance tab and see it help.
wailer
75 Posts
Quote from wailer on October 24, 2020, 7:11 amThank you,
The pool shows inactive when you open pools page, then, after about 10 seconds, shows active.
Have tried to slow down recovery traffic as you said, one of the nodes is really loaded. iSCSI disks appear sometimes now...
Thank you,
The pool shows inactive when you open pools page, then, after about 10 seconds, shows active.
Have tried to slow down recovery traffic as you said, one of the nodes is really loaded. iSCSI disks appear sometimes now...
admin
2,930 Posts
Quote from admin on October 24, 2020, 10:25 amWhat is the status at the ceph layer, do you still get slow ops reported or is it ok ?
What is utilization load bottleneck: cpu, network, disk, ram ?
How many OSD nodes do you have and how many OSDs per node ?
How many iSCSI nodes ?
Can you reduce client load ? can you move paths from loaded node ?
What is the replication level : x3 ?
Is the down node up now ?
What is the status at the ceph layer, do you still get slow ops reported or is it ok ?
What is utilization load bottleneck: cpu, network, disk, ram ?
How many OSD nodes do you have and how many OSDs per node ?
How many iSCSI nodes ?
Can you reduce client load ? can you move paths from loaded node ?
What is the replication level : x3 ?
Is the down node up now ?
wailer
75 Posts
Quote from wailer on October 24, 2020, 5:56 pmWhat is the status at the ceph layer, do you still get slow ops reported or is it ok ?
Yes here is ceph health detail:
HEALTH_WARN Degraded data redundancy: 3245122/48212490 objects degraded (6.731%), 227 pgs degraded, 228 pgs undersized; 1 slow ops, oldest one blocked for 10
7925 sec, mon.CEPH-12 has slow ops
PG_DEGRADED Degraded data redundancy: 3245122/48212490 objects degraded (6.731%), 227 pgs degraded, 228 pgs undersized
pg 1.2d5 is active+undersized+degraded+remapped+backfill_wait, acting [18,4]
pg 1.2d6 is stuck undersized for 107951.473880, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,16]
pg 1.2dc is stuck undersized for 107948.162212, current state active+undersized+degraded+remapped+backfill_wait, last acting [5,21]
pg 1.2dd is stuck undersized for 107948.129835, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,17]
pg 1.2e5 is stuck undersized for 107948.111425, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,23]
pg 1.2ea is stuck undersized for 107948.152514, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,17]
pg 1.2fa is stuck undersized for 107948.155469, current state active+undersized+degraded+remapped+backfill_wait, last acting [3,19]
pg 1.2fc is stuck undersized for 107948.133065, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,16]
pg 1.2fe is stuck undersized for 107948.141732, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,16]
pg 1.304 is stuck undersized for 107943.325286, current state active+undersized+degraded+remapped+backfill_wait, last acting [20,4]
pg 1.308 is stuck undersized for 107948.731479, current state active+undersized+degraded+remapped+backfill_wait, last acting [22,6]
pg 1.30b is stuck undersized for 107951.535692, current state active+undersized+degraded+remapped+backfill_wait, last acting [5,23]
pg 1.313 is stuck undersized for 107948.154676, current state active+undersized+degraded+remapped+backfill_wait, last acting [0,23]
pg 1.317 is stuck undersized for 107946.307538, current state active+undersized+degraded+remapped+backfilling, last acting [17,1]
pg 1.31a is stuck undersized for 107944.287470, current state active+undersized+degraded+remapped+backfill_wait, last acting [23,7]
pg 1.326 is stuck undersized for 107948.107936, current state active+undersized+degraded+remapped+backfill_wait, last acting [7,18]
pg 1.327 is stuck undersized for 107949.852230, current state active+undersized+degraded+remapped+backfill_wait, last acting [17,6]
pg 1.335 is stuck undersized for 107948.113297, current state active+undersized+degraded+remapped+backfill_wait, last acting [3,23]
pg 1.33b is stuck undersized for 107946.692066, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,23]
pg 1.342 is stuck undersized for 107948.159769, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,19]
pg 1.344 is stuck undersized for 107939.597347, current state active+undersized+degraded+remapped+backfill_wait, last acting [22,3]
pg 1.349 is stuck undersized for 107951.489330, current state active+undersized+degraded+remapped+backfill_wait, last acting [2,19]
pg 1.34b is stuck undersized for 107948.159365, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,19]
pg 1.34c is stuck undersized for 107945.134625, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,16]
pg 1.361 is stuck undersized for 107944.853218, current state active+undersized+degraded+remapped+backfill_wait, last acting [23,5]
pg 1.363 is stuck undersized for 107947.639559, current state active+undersized+degraded+remapped+backfill_wait, last acting [18,6]
pg 1.364 is stuck undersized for 107950.079675, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,19]
pg 1.372 is stuck undersized for 107948.623616, current state active+undersized+degraded+remapped+backfill_wait, last acting [16,3]
pg 1.379 is stuck undersized for 107941.358181, current state active+undersized+degraded+remapped+backfill_wait, last acting [2,20]
pg 1.37a is stuck undersized for 107945.135502, current state active+undersized+degraded+remapped+backfill_wait, last acting [7,19]
pg 1.37b is stuck undersized for 107945.135058, current state active+undersized+degraded+remapped+backfill_wait, last acting [0,22]
pg 1.383 is stuck undersized for 107946.003141, current state active+undersized+degraded+remapped+backfill_wait, last acting [16,7]
pg 1.397 is stuck undersized for 107943.956306, current state active+undersized+degraded+remapped+backfill_wait, last acting [18,2]
pg 1.3a6 is stuck undersized for 107950.878611, current state active+undersized+degraded+remapped+backfill_wait, last acting [18,7]
pg 1.3a9 is stuck undersized for 107944.678313, current state active+undersized+degraded+remapped+backfill_wait, last acting [22,0]
pg 1.3b0 is stuck undersized for 107945.297371, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,18]
pg 1.3b3 is stuck undersized for 107948.135891, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,17]
pg 1.3bc is stuck undersized for 107946.695125, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,18]
pg 1.3be is stuck undersized for 107951.502614, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,18]
pg 1.3c0 is stuck undersized for 107947.195574, current state active+undersized+degraded+remapped+backfill_wait, last acting [18,6]
pg 1.3c1 is stuck undersized for 107948.160991, current state active+undersized+degraded+remapped+backfill_wait, last acting [7,21]
pg 1.3c4 is stuck undersized for 107948.135944, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,19]
pg 1.3c5 is stuck undersized for 107943.564031, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,22]
pg 1.3cd is stuck undersized for 107944.929907, current state active+undersized+degraded+remapped+backfill_wait, last acting [17,3]...
...
What is utilization load bottleneck: cpu, network, disk, ram ?
CPU at node 2. When I slow down backfilling, CPU load is somehow reduced too, at this node.
How many OSD nodes do you have and how many OSDs per node ?
36 OSD's (10TB disks) - 12 OSD's per node
OS disk is 480GB enterprise SSD (RAID1)
How many iSCSI nodes ?
All 3 nodes hold iscsi role
Can you reduce client load ?
I reduced it all I could right now
can you move paths from loaded node ?
I am unable to access path config page to move them , graphs / UI are currently misbehaving with timeouts.
What is the replication level : x3 ?
Yes it's x3
Is the down node up now ?
Yes all nodes are up.
Thanks!
What is the status at the ceph layer, do you still get slow ops reported or is it ok ?
Yes here is ceph health detail:
HEALTH_WARN Degraded data redundancy: 3245122/48212490 objects degraded (6.731%), 227 pgs degraded, 228 pgs undersized; 1 slow ops, oldest one blocked for 10
7925 sec, mon.CEPH-12 has slow ops
PG_DEGRADED Degraded data redundancy: 3245122/48212490 objects degraded (6.731%), 227 pgs degraded, 228 pgs undersized
pg 1.2d5 is active+undersized+degraded+remapped+backfill_wait, acting [18,4]
pg 1.2d6 is stuck undersized for 107951.473880, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,16]
pg 1.2dc is stuck undersized for 107948.162212, current state active+undersized+degraded+remapped+backfill_wait, last acting [5,21]
pg 1.2dd is stuck undersized for 107948.129835, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,17]
pg 1.2e5 is stuck undersized for 107948.111425, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,23]
pg 1.2ea is stuck undersized for 107948.152514, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,17]
pg 1.2fa is stuck undersized for 107948.155469, current state active+undersized+degraded+remapped+backfill_wait, last acting [3,19]
pg 1.2fc is stuck undersized for 107948.133065, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,16]
pg 1.2fe is stuck undersized for 107948.141732, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,16]
pg 1.304 is stuck undersized for 107943.325286, current state active+undersized+degraded+remapped+backfill_wait, last acting [20,4]
pg 1.308 is stuck undersized for 107948.731479, current state active+undersized+degraded+remapped+backfill_wait, last acting [22,6]
pg 1.30b is stuck undersized for 107951.535692, current state active+undersized+degraded+remapped+backfill_wait, last acting [5,23]
pg 1.313 is stuck undersized for 107948.154676, current state active+undersized+degraded+remapped+backfill_wait, last acting [0,23]
pg 1.317 is stuck undersized for 107946.307538, current state active+undersized+degraded+remapped+backfilling, last acting [17,1]
pg 1.31a is stuck undersized for 107944.287470, current state active+undersized+degraded+remapped+backfill_wait, last acting [23,7]
pg 1.326 is stuck undersized for 107948.107936, current state active+undersized+degraded+remapped+backfill_wait, last acting [7,18]
pg 1.327 is stuck undersized for 107949.852230, current state active+undersized+degraded+remapped+backfill_wait, last acting [17,6]
pg 1.335 is stuck undersized for 107948.113297, current state active+undersized+degraded+remapped+backfill_wait, last acting [3,23]
pg 1.33b is stuck undersized for 107946.692066, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,23]
pg 1.342 is stuck undersized for 107948.159769, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,19]
pg 1.344 is stuck undersized for 107939.597347, current state active+undersized+degraded+remapped+backfill_wait, last acting [22,3]
pg 1.349 is stuck undersized for 107951.489330, current state active+undersized+degraded+remapped+backfill_wait, last acting [2,19]
pg 1.34b is stuck undersized for 107948.159365, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,19]
pg 1.34c is stuck undersized for 107945.134625, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,16]
pg 1.361 is stuck undersized for 107944.853218, current state active+undersized+degraded+remapped+backfill_wait, last acting [23,5]
pg 1.363 is stuck undersized for 107947.639559, current state active+undersized+degraded+remapped+backfill_wait, last acting [18,6]
pg 1.364 is stuck undersized for 107950.079675, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,19]
pg 1.372 is stuck undersized for 107948.623616, current state active+undersized+degraded+remapped+backfill_wait, last acting [16,3]
pg 1.379 is stuck undersized for 107941.358181, current state active+undersized+degraded+remapped+backfill_wait, last acting [2,20]
pg 1.37a is stuck undersized for 107945.135502, current state active+undersized+degraded+remapped+backfill_wait, last acting [7,19]
pg 1.37b is stuck undersized for 107945.135058, current state active+undersized+degraded+remapped+backfill_wait, last acting [0,22]
pg 1.383 is stuck undersized for 107946.003141, current state active+undersized+degraded+remapped+backfill_wait, last acting [16,7]
pg 1.397 is stuck undersized for 107943.956306, current state active+undersized+degraded+remapped+backfill_wait, last acting [18,2]
pg 1.3a6 is stuck undersized for 107950.878611, current state active+undersized+degraded+remapped+backfill_wait, last acting [18,7]
pg 1.3a9 is stuck undersized for 107944.678313, current state active+undersized+degraded+remapped+backfill_wait, last acting [22,0]
pg 1.3b0 is stuck undersized for 107945.297371, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,18]
pg 1.3b3 is stuck undersized for 107948.135891, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,17]
pg 1.3bc is stuck undersized for 107946.695125, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,18]
pg 1.3be is stuck undersized for 107951.502614, current state active+undersized+degraded+remapped+backfill_wait, last acting [6,18]
pg 1.3c0 is stuck undersized for 107947.195574, current state active+undersized+degraded+remapped+backfill_wait, last acting [18,6]
pg 1.3c1 is stuck undersized for 107948.160991, current state active+undersized+degraded+remapped+backfill_wait, last acting [7,21]
pg 1.3c4 is stuck undersized for 107948.135944, current state active+undersized+degraded+remapped+backfill_wait, last acting [1,19]
pg 1.3c5 is stuck undersized for 107943.564031, current state active+undersized+degraded+remapped+backfill_wait, last acting [4,22]
pg 1.3cd is stuck undersized for 107944.929907, current state active+undersized+degraded+remapped+backfill_wait, last acting [17,3]
...
...
What is utilization load bottleneck: cpu, network, disk, ram ?
CPU at node 2. When I slow down backfilling, CPU load is somehow reduced too, at this node.
How many OSD nodes do you have and how many OSDs per node ?
36 OSD's (10TB disks) - 12 OSD's per node
OS disk is 480GB enterprise SSD (RAID1)
How many iSCSI nodes ?
All 3 nodes hold iscsi role
Can you reduce client load ?
I reduced it all I could right now
can you move paths from loaded node ?
I am unable to access path config page to move them , graphs / UI are currently misbehaving with timeouts.
What is the replication level : x3 ?
Yes it's x3
Is the down node up now ?
Yes all nodes are up.
Thanks!
admin
2,930 Posts
Quote from admin on October 25, 2020, 9:45 amyou should lower the load, either client load or recovery load. Monitor the Ceph status as well as the PG Status chart to make sure Ceph is recovering and not stuck.
you should lower the load, either client load or recovery load. Monitor the Ceph status as well as the PG Status chart to make sure Ceph is recovering and not stuck.
wailer
75 Posts
Quote from wailer on October 25, 2020, 7:31 pmThank you, I set backfill speed to very slow, I will wait until the cluster finishes restoring, I guess it will take some days...as it looks to be working, just slowly..(around 40 pg's per day)
Thank you, I set backfill speed to very slow, I will wait until the cluster finishes restoring, I guess it will take some days...as it looks to be working, just slowly..(around 40 pg's per day)
wailer
75 Posts
Quote from wailer on October 27, 2020, 9:08 amHi again,
Seems that backfilling has finished, but UI is still not working correctly. Also graphs are giving bad gateway error.
Current cluster status is:
Affected node is still having extremely high CPU load. How can I find or unstuck this slow op?
Thanks!
EDIT: Checking ceph logs, looks like there's some recovery tasks going on yet:
2020-10-27 10:51:50.537092 mgr.CEPH-12 (mgr.22689265) 113372 : cluster [DBG] pgmap v101792: 1024 pgs: 2 active+clean+scrubbing+deep, 2 active+remapped+backfilling, 39 active+remapped+backfill_wait, 981 active+clean; 55 TiB data, 152 TiB used, 176 TiB / 327 TiB avail; 13 MiB/s rd, 26 MiB/s wr, 299 op/s; 631567/48321099 objects misplaced (1.307%); 22 MiB/s, 6 objects/s recovering.
Maybe this is the reason of the high load?
Hi again,
Seems that backfilling has finished, but UI is still not working correctly. Also graphs are giving bad gateway error.
Current cluster status is:
Affected node is still having extremely high CPU load. How can I find or unstuck this slow op?
Thanks!
EDIT: Checking ceph logs, looks like there's some recovery tasks going on yet:
2020-10-27 10:51:50.537092 mgr.CEPH-12 (mgr.22689265) 113372 : cluster [DBG] pgmap v101792: 1024 pgs: 2 active+clean+scrubbing+deep, 2 active+remapped+backfilling, 39 active+remapped+backfill_wait, 981 active+clean; 55 TiB data, 152 TiB used, 176 TiB / 327 TiB avail; 13 MiB/s rd, 26 MiB/s wr, 299 op/s; 631567/48321099 objects misplaced (1.307%); 22 MiB/s, 6 objects/s recovering.
Maybe this is the reason of the high load?
admin
2,930 Posts
Quote from admin on October 27, 2020, 1:43 pmdoes ceph status show you all pgs clean or does it show backfill recovery ?
does ceph status show you all pgs clean or does it show backfill recovery ?
wailer
75 Posts
Quote from wailer on October 27, 2020, 6:16 pmLooks like all backfills have finished now, the load on this node is still persisting, also the slow op reported.
root@CEPH-12:~# ceph health
HEALTH_WARN 126 pgs not scrubbed in time; 1 slow ops, oldest one blocked for 368671 sec, mon.CEPH-12 has slow opsroot@CEPH-12:~# ceph -s
cluster:
id: 5e2d37a0-a9ca-4ebf-814d-892d1da42032
health: HEALTH_WARN
128 pgs not scrubbed in time
1 slow ops, oldest one blocked for 368545 sec, mon.CEPH-12 has slow opsservices:
mon: 3 daemons, quorum CEPH-13,CEPH-11,CEPH-12 (age 4d)
mgr: CEPH-12(active, since 4d), standbys: CEPH-13, CEPH-11
osd: 36 osds: 36 up (since 4d), 36 in (since 4d)data:
pools: 1 pools, 1024 pgs
objects: 16.10M objects, 55 TiB
usage: 151 TiB used, 176 TiB / 327 TiB avail
pgs: 1014 active+clean
6 active+clean+scrubbing+deep
4 active+clean+scrubbingio:
client: 15 MiB/s rd, 9.8 MiB/s wr, 104 op/s rd, 63 op/s wrThanks!
Looks like all backfills have finished now, the load on this node is still persisting, also the slow op reported.
root@CEPH-12:~# ceph health
HEALTH_WARN 126 pgs not scrubbed in time; 1 slow ops, oldest one blocked for 368671 sec, mon.CEPH-12 has slow ops
root@CEPH-12:~# ceph -s
cluster:
id: 5e2d37a0-a9ca-4ebf-814d-892d1da42032
health: HEALTH_WARN
128 pgs not scrubbed in time
1 slow ops, oldest one blocked for 368545 sec, mon.CEPH-12 has slow ops
services:
mon: 3 daemons, quorum CEPH-13,CEPH-11,CEPH-12 (age 4d)
mgr: CEPH-12(active, since 4d), standbys: CEPH-13, CEPH-11
osd: 36 osds: 36 up (since 4d), 36 in (since 4d)
data:
pools: 1 pools, 1024 pgs
objects: 16.10M objects, 55 TiB
usage: 151 TiB used, 176 TiB / 327 TiB avail
pgs: 1014 active+clean
6 active+clean+scrubbing+deep
4 active+clean+scrubbing
io:
client: 15 MiB/s rd, 9.8 MiB/s wr, 104 op/s rd, 63 op/s wr
Thanks!